Experimentos sobre el algoritmo de división de texto¶
En la sección relativa a la Codificación del texto de la Memoria, se introduce el problema que presentan muchos de los modelos de generación del lenguaje, entre ellos el modelo T5, el cual utilizamos.
Dicho problema deriva del hecho de que estos modelos admiten un número de tókenes de entrada máximo, 512 en el caso del modelo T5.
Por tanto, desarrollamos un algoritmo que divide el texto en fragmentos, sin que ninguna frase quede partida, y siendo las diferencias entre el número de tókenes en cada una de las divisiones tan pequeñas como sea posible.
Para ello, primero dividimos el texto de manera voraz, de forma que se van añadiendo frases a una subdivisión siempre que estas quepan sin ser fragmentadas.
Esto puede resultar en que la última subdivisión contenga un número de frases muy inferior a la del resto de subdivisiones. Para solucionar este problema, se realiza un <<balanceo>> de las subdivisiones, moviendo frases de unas a otras, pero conservando su orden.
La muestra el proceso de manera visual a través de un ejemplo:
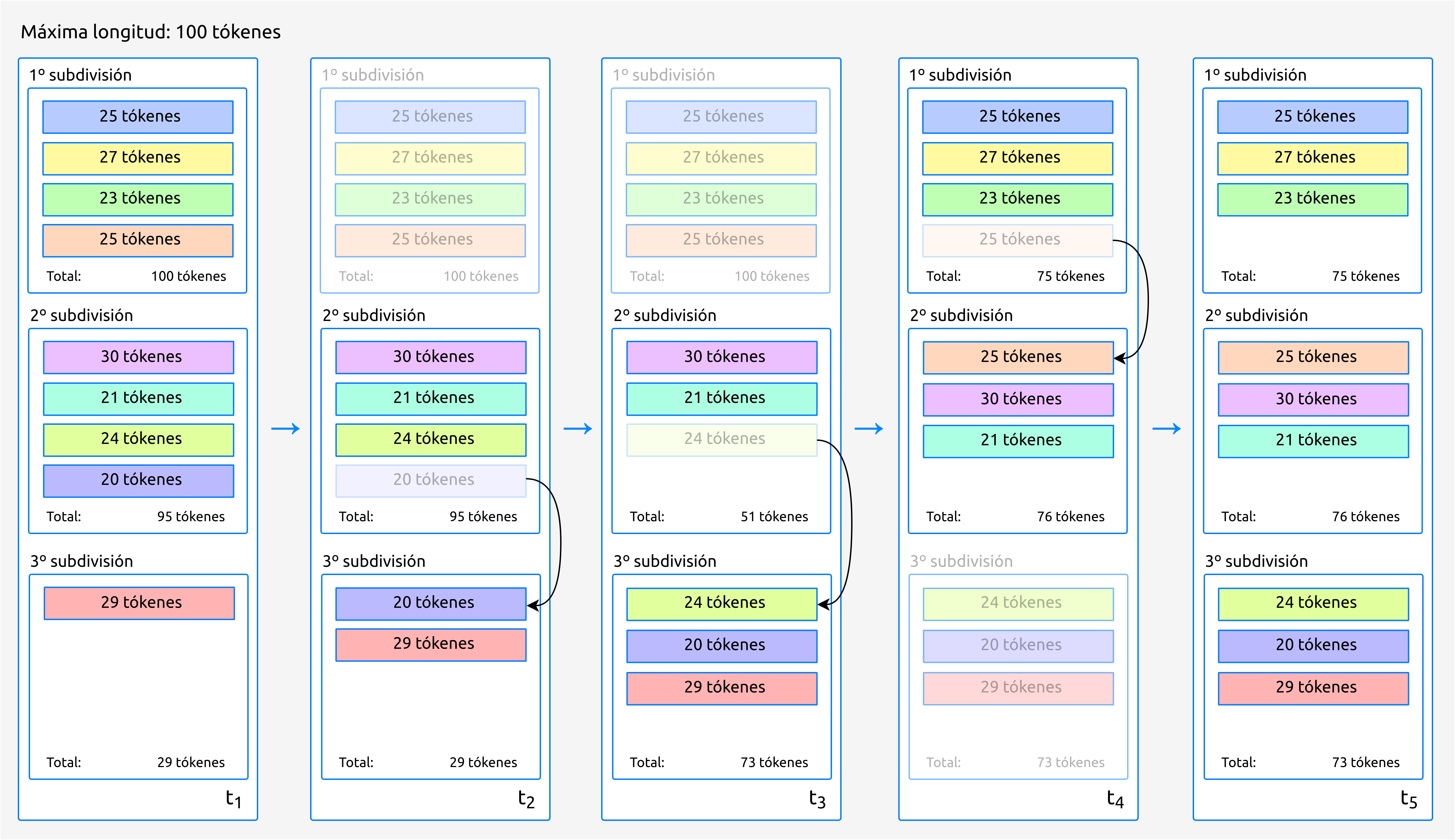
Figura 64 Proceso de balanceo de las subdivisones generadas de forma voraz. Ejemplo con una longitud máxima de 100 tókenes.¶
En las tablas recogidas en las siguientes páginas, se muestra el número de tókenes por subdivisión resultante de aplicar la división voraz, y el número de tókenes por subdivisión una vez realizado el balanceo. Para los textos de los experimentos, se emplearon hilos de Twitter, teniendo el más corto 191 palabras, y artículos extraídos de Internet, el más largo de los cuales contiene 46.911 palabras.
Las diferencias entre el número de tókenes antes y después de realizar la división son claras, lo que indica el correcto funcionamiento del algoritmo propuesto. Además, el incremento de tiempo que introduce el balanceo es, por lo general, mínimo1.
Palabras (tókenes) |
Voraz |
Balanceado |
|
|---|---|---|---|
191 (280) |
Tókenes/subdiv. |
[280] |
[280] |
Desv. estándar |
0,0 |
0,0 |
|
Tiempo |
5,23 ms |
5,23 ms |
|
394 (534) |
Tókenes/subdiv. |
[506, 28] |
[273, 261] |
Desv. estándar |
239,0 |
6,0 |
|
Tiempo |
8,15 ms |
8,21 ms |
|
646(906) |
Tókenes/subdiv. |
[504, 402] |
[448, 458] |
Desv. estándar |
51,0 |
5,0 |
|
Tiempo |
13,4 ms |
13,8 ms |
|
1.089(1.417) |
Tókenes/subdiv. |
[488, 477, 452] |
[478, 487, 452] |
Desv. estándar |
15,06 |
14,84 |
|
Tiempo |
26,10 ms |
25,70 ms |
|
1.536 (2.069) |
Tókenes/subdiv. |
[509, 508, 507, 501, 44] |
[437, 419, 409, 407, 397] |
Desv. estándar |
184,92 |
13,54 |
|
Tiempo |
41 ms |
41,2 ms |
|
1.871 (4.531) |
Tókenes/subdiv. |
[409, 426, … , 475, 414] |
[409, 426, … , 422, 467] |
Desv. estándar |
39,70 |
32,11 |
|
Tiempo |
34,7 ms |
35,4 ms |
|
2,060 (2,060) |
Tókenes/subdiv. |
[501, 497, … , 402, 509] |
[501, 497, … , 402, 509] |
Desv. estándar |
54,40 |
37,65 |
|
Tiempo |
26,1 ms |
26,7 ms |
|
3,753 (5,293) |
Tókenes/subdiv. |
[504, 505, … , 503, 386] |
[504, 505, … , 469, 437] |
Desv. estándar |
36,75 |
19,72 |
|
Tiempo |
62,1 ms |
62,9 ms |
Palabras (tókenes) |
Voraz |
Balanceado |
|
|---|---|---|---|
5.022 (8.051) |
Tókenes/subdiv. |
[498, 499, … , 497, 77] |
[498, 499, … , 418, 396] |
Desv. estándar |
99,88 |
39,21 |
|
Tiempo |
118 ms |
120 ms |
|
10.058 (15.761) |
Tókenes/subdiv. |
[498, 499, … , 496, 415] |
[498, 499, … , 461, 484] |
Desv. estándar |
23,54 |
15,52 |
|
Tiempo |
250 ms |
251 ms |
|
20.203 (30.989) |
Tókenes/subdiv. |
[498, 499, … , 481, 311] |
[498, 499, … , 425, 420] |
Desv. estándar |
29,51 |
18,95 |
|
Tiempo |
470 ms |
488 ms |
|
46.911 (69.772) |
Tókenes/subdiv. |
[498, 499, … , 505, 121] |
[498, 499, … , 392, 385] |
Desv. estándar |
35,05 |
17,01 |
|
Tiempo |
1,08 s |
1,11 s |
Por último, queremos mencionar que, al comienzo del proyecto, escribimos diferentes notebooks de Jupyter que explican cómo llegamos a ciertas conclusiones a la hora de realizar el pre-procesado y post-procesado de los textos, así como un pequeño estudio comparativo realizado con dos modelos de generación de textos. Se puede acceder a dichos notebooks a través de https://https://github.com/dmlls/jizt-tfg/tree/main/notebooks.
- 1
Posteriormente a la realización de este experimento, se optimizó notablemente el rendimiento global del algoritmo para el modelo T5. Para más información, se puede consultar la siguiente Issue en el repositorio del proyecto en GitHub: https://https://github.com/dmlls/jizt-tfg/issues/97.