Técnicas y herramientas¶
En este capítulo, se recogen las tecnologías principales empleadas en el desarrollo del proyecto, así como los detalles más relevantes de su implementación.
Para facilitar la organización y comprensión de las mismas, se han separado en tres subsecciones: Modelo, en la que se detalla el funcionamiento del modelo de generación de lenguaje empleado, Backend, donde profundizamos en la implementación del servicio escalable en la nube, y Frontend, en la que explicamos todo lo referente a la aplicación multiplataforma desarrollada.
Modelo de generación de resúmenes¶
Como se ha venido mencionando a lo largo de los anteriores capítulos, para la
generación de resúmenes se ha elegido el modelo T5 de Google. Más concretamente,
utilizamos la implementación t5-large de Hugging Face [t5-hf], el cual
ha sido entrenado con texto en inglés procedente del Colossal Clean Crawled Corpus
(C4), y contiene aproximadamente 770 millones de parámetros [hf-pretrained].
Esta implementación está escrita en Python, lo que nos facilita la integración con el resto de componentes del backend de JIZT, también desarrollados en Python.
El modelo t5-large consta, por un lado, del tokenizer, encargado
de la codificación del texto, y por otro, del modelo en sí, el cual
recibe el texto codificado por el tokenizer, y genera el resumen a
partir de él. Dicho resumen, sigue estando en forma de tókenes
codificados, por lo que tenemos que hacer uso una vez más del
tokenizer para proceder a su decodificación. Una vez decodificado, el
texto vuelve a contener caracteres legibles.
Tanto el proceso de codificación, como el de generación de resúmenes, se han implementado de forma que se puedan llevar a cabo empleando unidades de procesamiento gráfico (GPU). No obstante, en nuestro caso y por el momento, ambos procesos se ejecutan en unidades centrales de procesamiento (CPU), debido a limitaciones económicas1. Esto explica en parte los tiempos de resumen obtenidos, los cuales pueden resultar algo dilatados con textos muy largos.
Un último aspecto a destacar es que a la hora de generar los resúmenes, se pueden especificar los parámetros concretos con los que realizar dicha generación, permitiéndonos hacer uso de las Principales estrategias de generación de resúmenes vistas anteriormente.
Backend — Plataforma escalable en la nube¶
En la figura mostrada a continuación, se recoge una visión general de la arquitectura que conforma el backend de JIZT, y que posibilita la implementación en la nube de las diferentes etapas en la generación de resúmenes descritas en el capítulo de Conceptos teóricos.
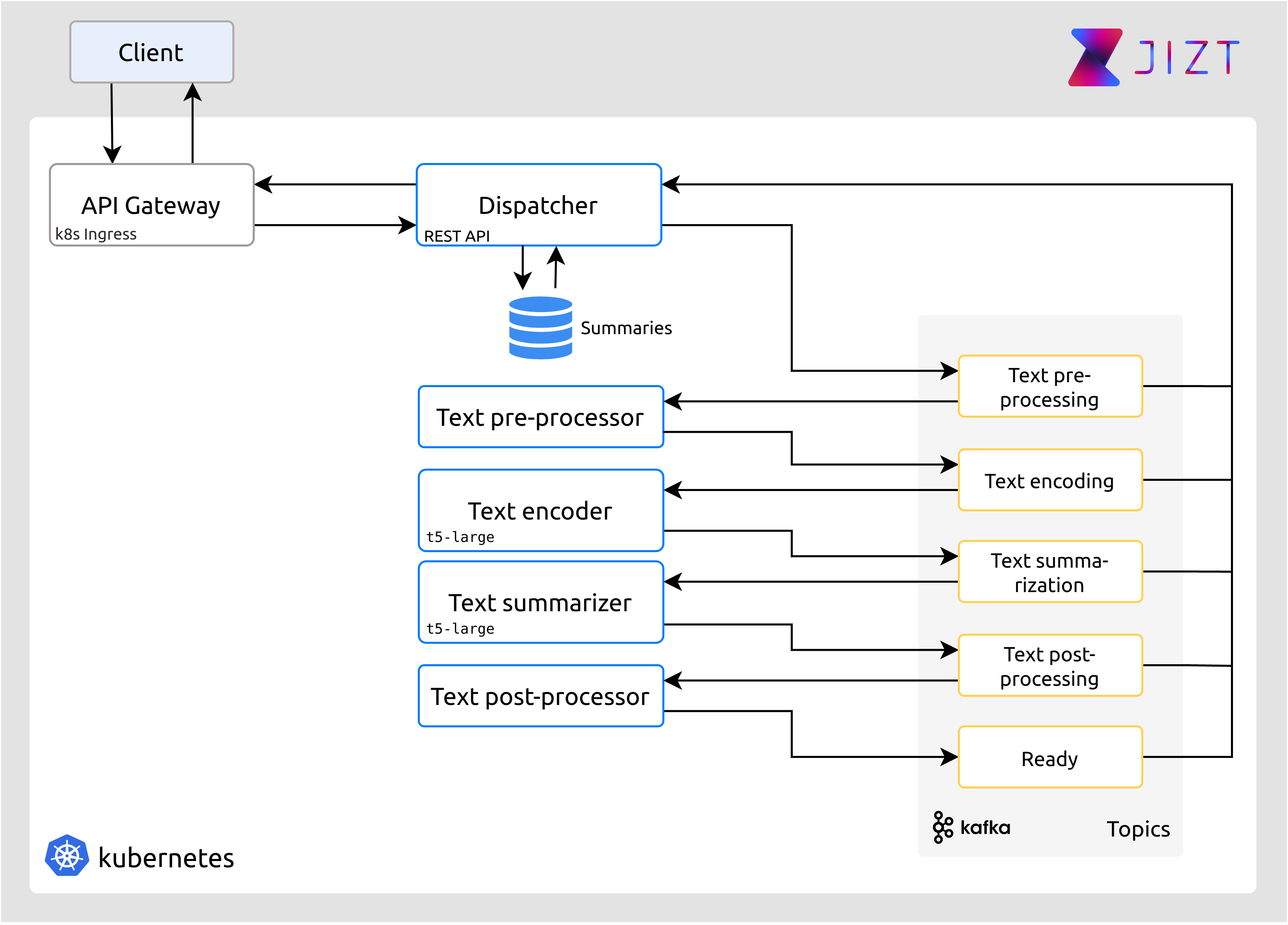
Figura 17 Vista general de la arquitectura del backend. Los rectángulos en azul se corresponden con los microservicios de JIZT. Los rectángulos en amarillo, representan los topics de Kafka, explicados posteriormente.¶
En esta arquitectura, existen diferentes tecnologías, cada una encargada de realizar una tarea específica, pero a su vez integrándose con el resto. A grandes rasgos, y sin ser necesario que el lector comprenda con exactitud todos los términos por ahora, presentemos brevemente cuáles son las tecnologías empleadas.
En primer lugar, cada microservicio se encapsula en un contenedor Docker. De esta forma, además de modularizar cada microservicio, podemos aumentar el número de réplicas de cada uno de ellos, permitiendo el escalado de la arquitectura.
Por su parte, Kubernetes se encarga de la orquestración de los microservicios, ocupándose de aspectos como la replicación, configuración de red y almacenamiento, gestión de los recursos del sistema, etc. El despliegue de los componentes que componen Kubernetes se simplifica gracias al uso de otra herramienta, Helm.
Otra de las tecnologías usadas, Apache Kafka, permite la comunicación entre los diferentes microservicios mediante eventos.
El despliegue de la base de datos PostgreSQL en Kubernetes encargada de almacenar los resúmenes generados, corre a cargo del Operador de PostgreSQL de Crunchy.
Por último, la API REST se implementa a través de un popular framework para Python, llamado Flask.
Expliquemos, ahora sí, de forma detallada cómo funciona cada una de estas tecnologías.
Docker¶
Docker nos permite encapsular nuestros microservicios en contenedores. De este modo, gracias a Kubernetes, podemos crear réplicas de cada microservicio, haciendo posible el escalado de nuestro sistema.
A diferencia de las máquinas virtuales, en las cuales el sistema operativo subyacente se comparte a través del hipervisor, cada contenedor Docker ejecuta su propio sistema operativo, como podemos ver en la siguiente figura:
![Comparativa de los diferentes enfoques en el despliegue de sistemas: desarrollo tradicional, desarrollo virtualizado, y desarrollo con contenedores [kubernetes]_.](../_images/docker.png)
Figura 18 Comparativa de los diferentes enfoques en el despliegue de sistemas: desarrollo tradicional, desarrollo virtualizado, y desarrollo con contenedores [kubernetes].¶
Otra ventaja de Docker es que nos permite distribuir la implementación de nuestros microservicios a través imágenes, por lo que un desarrollador que solo quisiera hacer uso de uno de los microservicios, podría hacerlo de manera sencilla.
Kubernetes¶
El backend sigue una arquitectura de microservicios [newman15], de forma que cada una de las etapas (pre-procesado, codificación, generación del resumen y post-procesado), está confinada en un contenedor Docker [docker], conformando un microservicio. Adicionalmente, existe un microservicio más, el Dispatcher, el cual lleva a cabo las siguientes tareas:
Implementa una API REST que permite a los clientes solicitar resúmenes.
Gestiona una base de datos en la que se almacenan los resúmenes generados.
Redirige las peticiones de los clientes al microservicio apropiado. Por ahora, todas las peticiones se redirigen hacia el pre-procesador de textos, pero en un futuro podría existir otro microservicio que se encargara, por ejemplo, de extraer el texto de un documento PDF o de una página web. En estos casos, el Dispatcher se encargaría de redirigirlo hacia el microservicio correspondiente.
Kubernetes es una plataforma open-source destinada a la gestión de servicios y cargas de trabajo en contenedores, facilitando su automatización en cuanto a aspectos como el escalado, gestión de red y recursos, monitorización, etc. [kubernetes].
Kubernetes comprende numerosos componentes, entre los cuales, los más relevantes para nuestro proyecto son:
Pod: es la unidad de computación básica en Kubernetes. Un Pod puede ejecutar uno o varios contenedores intrínsecamente relacionados (compartirán almacenamiento, red, recursos, etc.).
Deployment: los deployments se pueden ver como «plantillas» o «moldes» que contienen los detalles específicos para crear pods de un determinado tipo. Por ejemplo, en el caso del mencionado Dispatcher, dispondremos de un deployment que indicará cómo se deben crear los pods para este servicio, todos ellos idénticos. Estos pods a su vez, contendrán todos la misma imagen Docker que implementará la lógica del servicio.
Service: cada pod dispone de una dirección IP propia. Sin embargo, los pods tienen un ciclo de vida efímero, dado que están concebidos para ser reemplazados dinámicamente si se producen errores, actualizaciones, etc. Por tanto, no podemos basar la configuración de red en las IPs específicas de los pods, ya que estás son susceptibles de cambiar a lo largo del tiempo, según los pods vayan siendo reemplazados. Los services nos permiten asociar una IP fija y persistente a un conjunto concreto de pods. A la hora de realizar una conexión con dicha IP, Kubernetes se encarga de remitir los datos al pod que esté menos ocupado en ese instante, realizando por tanto un balance de carga de forma automática.
PersistentVolume: al igual que en el caso de las IPs, los datos almacenados localmente en un pod desaparecerán cuando este sea reemplazado. Los PersistentVolumes nos proporcionan la capacidad de almacenar datos de manera persistente, independientemente del ciclo de vida de los pods. Nosotros, utilizamos este componente para almacenar los modelos de generación de resúmenes, ya que ocupan alrededor de 5 GB, de forma que los pods correspondientes a la codificación de texto y generación del resumen consumen los modelos desde una única fuente de datos, el PersistentVolume. Incluir los modelos dentro de los propios pods sería contraproducente ya que (a) todos los pods van a hacer uso de los mismos modelos, y (b) los modelos tienen un tamaño del orden de gigas, por lo que si quisiéramos crear varios pods, la demanda de almacenamiento crecería rápida e innecesariamente.
La figura mostrada a continuación pretende facilitar la comprensión de los diferentes componentes de manera más visual. Como podemos ver en dicha figura, existen n pods, todos ellos replicas de un mismo deployment y, por tanto, ejecutando los mismos contenedores, pero cada uno de ellos con una dirección IP propia. El service permite acceder a los diferentes pods a través de una única IP estática. Por último, todos los pods consumen un mismo PersistentVolume que, por ejemplo, podría contener los modelos ya mencionados.
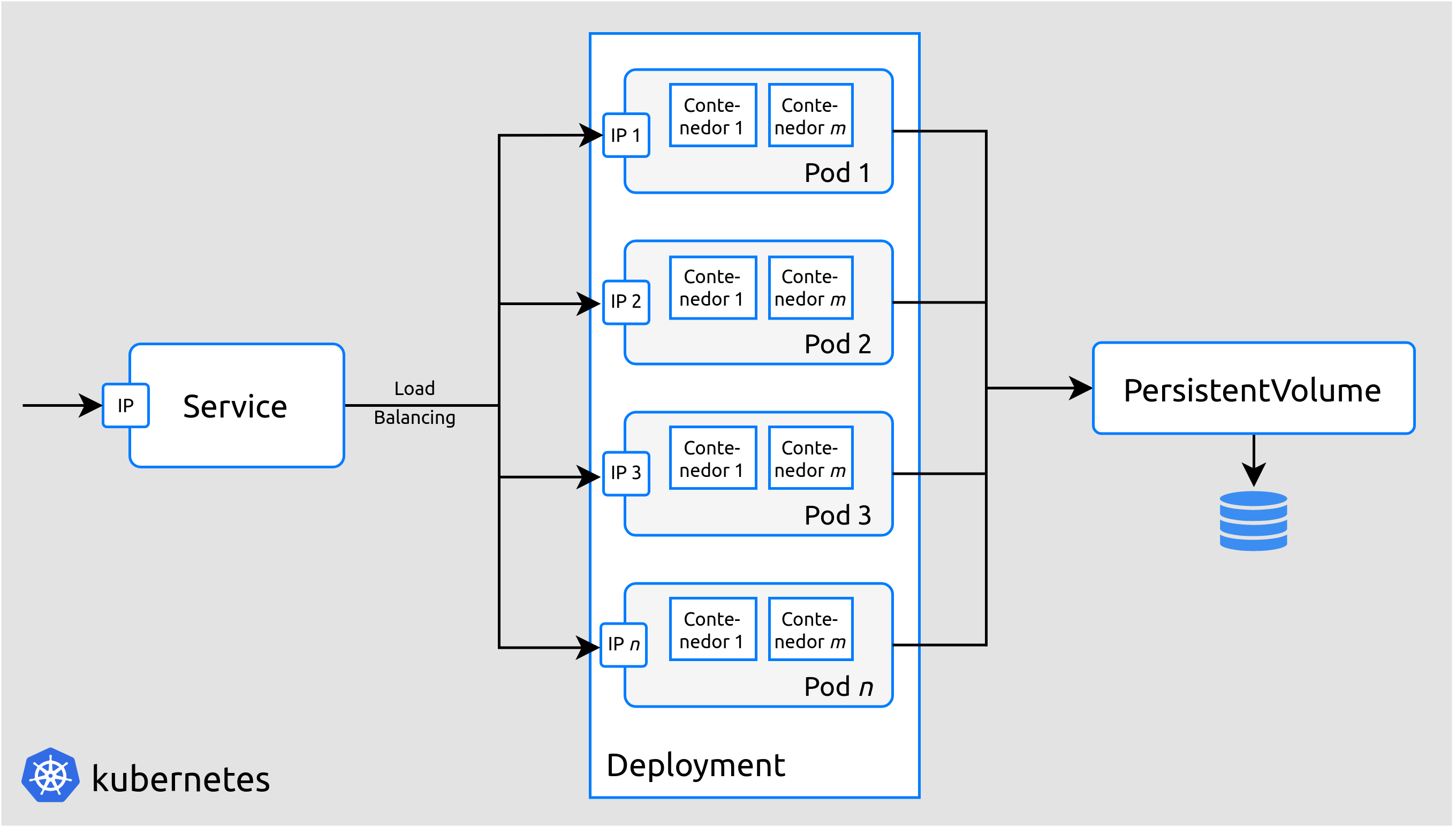
Figura 19 Componentes principales de Kubernetes.¶
De este modo, podemos escalar (o actualizar) cada uno de los microservicios de forma dinámica y sin periodos de inactividad (downtime). De hecho, Kubernetes permite configurar dicho escalado de manera automática. Así, en momentos en los que la carga de trabajo sea mayor, Kubernetes se encargará de crear pods adicionales para responder ante dicha carga y, una vez esta desaparezca, los volverá a eliminar. Al habilitar esta opción, es muy recomendable configurar el número máximo de pods que se podrán crear, a fin de evitar un escalado descontrolado en momentos de carga extrema (en cualquier caso, Kubernetes detendría la creación de pods tan pronto como se consumieran los recursos disponibles del sistema [k8s-scheduling]).
Existe un último componente de Kubernetes del que hacemos uso, llamado Ingress. Este componente implementa una API Gateway, enrutando las peticiones API de los clientes hacia el microservicio correspondiente [api-gateway]. Por ahora, la API REST que hemos implementado solo dispone de rutas relacionadas a la generación de resúmenes, pero en un futuro, cuando se implementen otras tareas de NLP, existirán otros endpoints para dichas tareas. Ingress se encargará entonces de, en función de a qué endpoint se esté realizando la petición, redirigirla al microservicio correspondiente.
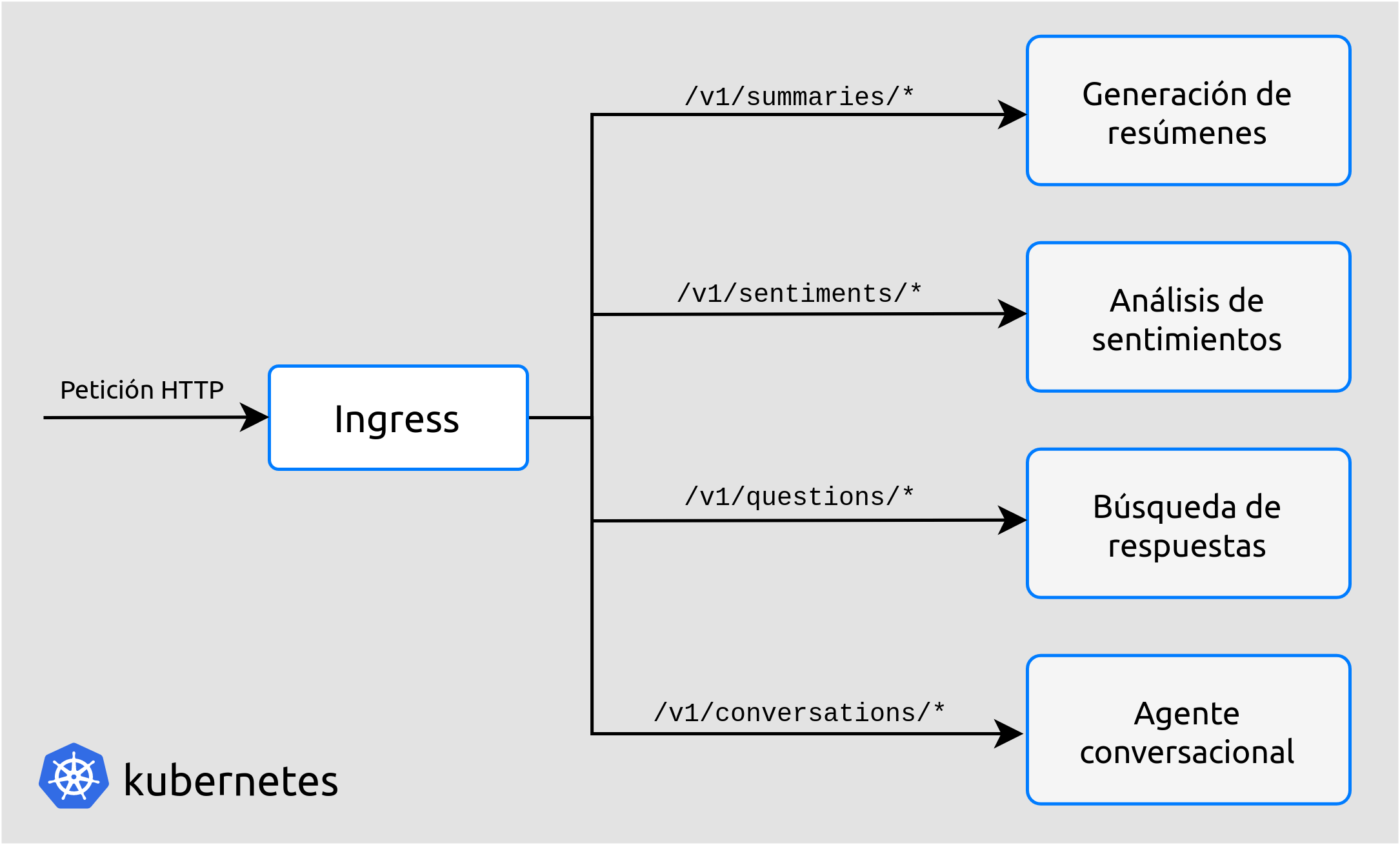
Figura 20 Ejemplo de un hipotético uso de Ingress con diferentes rutas.¶
Kafka y Strimzi¶
Uno de los principales aspectos a considerar a la hora de implementar una arquitectura de microservicios, reside en la estrategia que se va seguir para permitir la comunicación entre los diferentes microservicios.
Dicha comunicación puede llevarse a cabo de forma síncrona, por ejemplo a través de peticiones HTTP, o asíncrona, con tecnologías como Apache Kafka [microsoft-microsvcs].
En nuestro caso la comunicación síncrona quedó rápidamente descartada, dado que la generación de resúmenes presenta tiempos de latencia que pueden ser elevados (del orden de segundos o incluso minutos). Decidimos, por tanto, adoptar la segunda opción.
Apache Kafka nació internamente en LinkedIn, aunque actualmente es open-source y su desarrollo corre a cargo de la Apache Software Foundation [wiki-kafka].
Kafka permite el intercambio asíncrono de mensajes entre productores y consumidores. En esencia, su funcionamiento es conceptualmente sencillo y está alineado con tecnologías más tradicionales: los consumidores se subscriben a un tema (topic), a los que los productores envían sus mensajes. La consumición de dichos mensajes es asíncrona.
La novedad de Kafka reside, entre otras cosas, en su gran capacidad de escalado, pudiendo soportar billones de mensajes al día; su funcionamiento distribuido, de manera que puede operar fácilmente a lo largo de diferentes zonas geográficas; su gran fiabilidad en entornos críticos, en los que la pérdida de un solo mensaje es inadmisible; o su tolerancia frente a fallos [apache-kafka].
Todas estas demandas no suponen, sin embargo, que Kafka no se pueda aplicar de igual modo a entornos más reducidos, como es el nuestro. Además, gracias a Strimzi, otro proyecto también open-source, el despliegue de Kafka en Kubernetes se simplifica en gran medida.
Si volvemos a observar la figura que ilustra la arquitectura general del backend, podemos ver que JIZT dispone de cinco topics, los cuales se corresponden con cada una de las etapas en la generación resúmenes.
Figura 21 Vista general de la arquitectura del backend.¶
Con esta figura en mente, el proceso completo que se sigue es el siguiente:
El cliente realiza una petición HTTP POST solicitando un nuevo resumen. Para ello, debe incluir en el cuerpo el texto a resumir, y de manera opcional los parámetros del resumen a generar.
Ingress (API Gateway) comprueba que dicha petición se está haciendo a un endpoint válido, y en ese caso la redirige hacia el Dispatcher. En caso contrario devolverá un error HTTP 404.
El Dispatcher realiza una serie de comprobaciones:
Si la petición no contiene ningún texto, se devuelve un error. En el caso de los parámetros, si son incorrectos o inexistentes, se ignoran y se utilizan valores por defecto.
Se consulta en la base de datos si ya existe un resumen generado para ese texto con esos mismos parámetros. En ese caso, lo devuelve directamente, sin generar de nuevo el resumen.
En caso contrario, produce un mensaje al topic del pre-procesador de textos, conteniendo el texto y los parámetros del resumen.
El pre-procesador está constantemente comprobando si existen mensajes nuevos en su topic. En ese caso los consume, realiza las tareas de pre-procesado, y produce el resultado en el topic del codificador.
Este proceso continua de forma análoga hasta llegar al post-procesador, el cual produce el resumen final al topic «Listo» (Ready). El Dispatcher, en ese momento, consume el mensaje, actualiza la base de datos, y proporciona el resumen al cliente.
En dicha figura, vemos también que el Dispatcher consume de todos los topics. Esto permite actualizar el estado del resumen (pre-procesando, resumiendo, post-procesando, o listo), según va pasando por las diferentes etapas, a fin de proporcionar una retroalimentación más detallada al usuario.
Finalmente, cabe destacar una vez más la facilidad de escalado que nos proporciona Kafka: si, por ejemplo, ampliásemos nuestra arquitectura de modo que tuviéramos tres réplicas de cada microservicio, Kafka se encargaría automáticamente de coordinar la producción y consumición concurrente de mensajes de cada topic, sin que nosotros tuviéramos que llevar a cabo ninguna acción adicional.
Helm¶
Helm se define frecuentemente como un gestor de paquetes para Kubernetes, aunque en la práctica va más allá.
La configuración de Kubernetes se lleva a cabo, principalmente, de forma
declarativa a través de ficheros en formato yaml, lo que en inglés
se conoce como templating. Nuestro proyecto, el cual es relativamente
pequeño, hace uso de más de 20 de estos ficheros de configuración. Es
fácil imaginarse, por tanto, que un proyecto de mediana escala contendrá
cientos de templates.
Helm permite, a través de un único comando, desplegar todos estos componentes de forma automática, gestionando aspectos como el orden en el que se crean los componentes, el cual en muchos casos no es trivial. Una vez instalados, a través de otro comando, podemos actualizar los posibles cambios que haya sufrido alguno de los templates, de forma que solo afecte a los componentes involucrados en dichas modificaciones, y lleva a cabo la actualización sin tiempos de interrupción.
Además, a tráves de las llamadas Library Charts [helm-lib-charts], Helm nos permite generar una plantilla que varios componentes pueden reutilizar. Esto es muy apropiado en nuestro caso dado que todos nuestros microservicios tienen una estructura similar; lo único que cambia es la imagen (contenedor) que implementan.
Una última ventaja es que podemos distribuir el backend de JIZT como un único paquete, facilitando su instalación por parte de otros desarrolladores.
Crunchy PostgreSQL Operator¶
De igual modo que Strimzi facilita el despliegue de Kafka en Kubernetes, el operador para PostgreSQL de Crunchy automatiza y simplifica el despliegue de clústers PostgreSQL en Kubernetes [crunchy21].
De este modo, podemos implementar una base de datos que almacene los resúmenes generados2, con dos propósitos principales: (a) servir como capa de caché, evitando tener que producir el mismo resumen en repetidas ocasiones, y (b) construir un dataset que se podría utilizar en un futuro para tareas de evaluación, o incluso para el entrenamiento de otros modelos.
La estructura de tablas empleada para la base de datos se puede consultar en los Anexos, en el apéndice de Especificación de diseño.
Este operador coordina de forma automática los accesos a la base de datos, asegurando la integridad de la misma. Esto es posible dado que solo existe un única instancia (pod) con capacidades de escritura-lectura. El resto de instancias que accedan a la base de datos, solo podrán leer de la misma. Si la instancia primaria fallara, el operador se encargaría inmediatamente de elegir otra instancia como primaria.
Flask y Flask-RESTful¶
Flask es uno de los frameworks más populares para la creación de aplicaciones web en Python [flask], concebido para ser lo más simple posible. En nuestro caso, hemos empleado esta herramienta para implementar la lógica de la API REST. Además, hemos utilizado una conocida extensión de Flask, Flask-RESTful [flaskRestful], orientada a la construcción de APIs REST, como es nuestro caso.
Dado que es el Dispatcher quien implementa la API REST, es únicamente este microservicio el que hace uso de este framework.
Frontend — Aplicación multiplataforma¶
Flutter¶
Flutter es un kit de herramientas de UI (interfaz de usuario) que, a partir del mismo código fuente base, permite compilar de forma nativa aplicaciones para móvil, web y escritorio [flutter-es], lo cual permite [miola20]:
Un desarrollo más rápido, dado que solo se trabaja en una única base de código.
Costes más bajos, ya que solo mantenemos un proyecto en vez de varios.
Una mayor consistencia, proporcionando al usuario la misma interfaz gráfica y herramientas en las distintas plataformas, conservando los patrones de interacción de cada una de ellas.
Pese a ser desarrollado por Google desde su nacimiento en 2017, Flutter cuenta en la actualidad con un gran apoyo de la comunidad open-source. Esto ha contribuido en gran medida al desarrollo de Flutter, y en nuestro caso nos ha facilitado la resolución de dudas y errores a la hora de desarrollar nuestra aplicación.
Flutter emplea el lenguaje de programación Dart, un lenguaje orientado a objetos que guarda ciertas similitudes con otros lenguajes como Java o C#. Existen numerosos aspectos de Flutter y Dart que cabría explicar; no obstante, en pos de la brevedad introduciremos uno de los que más interesantes y relevantes nos parecen para este proyecto: ¿Cómo se consigue que Dart pueda ser ejecutado nativamente en plataformas que pueden resultar tan dispares como Android, iOS, web, Windows o GNU/Linux?
Para responder a esta pregunta, es importante comenzar indicando que en el contexto de Flutter, se opera de manera diferente en el entorno de desarrollo y en el entorno de producción.
Veamos cuáles son las diferencias principales.
Desarrollo nativo (plataformas x64/ARM)¶
Así como Java requiere de la JVM (Java Virtual Machine) para ejecutarse, Dart también dispone de su propia DVM (Dart Virtual Machine).
Durante la etapa de desarrollo, la máquina DVM se utiliza en combinación con un compilador JIT (Just In Time), es decir, se lleva a cabo una compilación en tiempo de ejecución, en lugar de antes de la ejecución. Esto permite tratar con el código de forma dinámica independientemente de la arquitectura de la máquina sobre la que se trabaje.
Además, esta forma de operar hace posible lo que se conoce como hot reload, que permite visualizar los cambios realizados en la aplicación de manera prácticamente instantánea, dado que los cambios en el código se transfieren a la DVM, pero se conserva el estado de la app [flutter-hot-reload]. Esto decrementa notablemente los tiempos empleados en el debug de las aplicaciones.
Desarrollo web¶
Durante el desarrollo, el compilador de desarrollo Dart, conocido como
dartdevc, permite ejecutar y depurar aplicaciones web Dart en
Google Chrome. Usado en combinación con otras herramientas como
webdev, el cual proporciona un servidor web de desarrollo, podemos
visualizar en nuestro navegador los cambios realizados en el código
fuente de manera casi inmediata.
Producción nativa (plataformas x64/ARM)¶
En este caso se emplea lo que se conoce como compilación anticipada (AOT, Ahead-of-time Compilation). Gracias a esta estrategia, el compilador de Dart es capaz de traducir un lenguaje de alto nivel, como en este caso Dart, a código máquina x64/ARM nativo [aot-wiki]. Este código máquina sí que será, a partir de este momento, dependiente del sistema.
Como consecuencia de lo anterior, en este caso ya no es necesario
emplear una DVM, ya que con la compilación AOT obtenemos, para cada
plataforma, un único binario ejecutable (.apk o .aab para
Android, .exe para Windows, etc.).
La compilación AOT es, por tanto, lo que realmente convierte a Flutter en una herramienta rápida y portable.
Producción web¶
El código Dart también puede ser traducido a HTML, CSS y JavaScript (en
el caso de este último gracias a una herramienta llamada dart2js).
Esto significa que podemos ejecutar nuestra aplicación en nuestro navegador3, y la interfaz gráfica será la misma que en el resto de plataformas.
Es importante mencionar, que el soporte para web de Flutter se encuentra aún en fase beta, por lo que no se recomienda para producción [flutter-web]. No obstante, nosotros no hemos experimentado problemas con nuestra aplicación en ninguno de los navegadores soportados.
- 1
Cabe recordar que los modelos se ejecutan en «la nube». Contratar equipos que dispongan de GPU aumentaría notablemente los costes.
- 2
Una de las futuras historias de usuario implementará un «modo privado», de forma que los usuarios tengan la posibilidad de generar sus resúmenes sin que se almacenen de manera permanente.
- 3
Por ahora, solo Chrome, Safari, Edge y Firefox están soportados [flutter-web].
- t5-hf
Hugging Face. Model t5-large. Feb. de 2021. URL: https://huggingface.co/t5-large. Último acceso: 03/02/2021.
- hf-pretrained
Hugging Face. Pretrained models. Feb. de 2021. URL: https://huggingface.co/transformers/pretrained_models.html. Último acceso: 03/02/2021.
- kubernetes(1,2)
Kubernetes. What is Kubernetes? Oct. de 2020. URL: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes. Último acceso: 03/02/2021.
- newman15
Sam Newman. Building Microservices. O’Reilly Media, Inc., feb. de 2015. ISBN: 9781491950357.
- docker
Docker. Why Docker? 2021. URL: https://www.docker.com/why-docker. Último acceso: 03/02/2021.
- k8s-scheduling
Kubernetes. Scheduling and Eviction. Jun. de 2020. URL: https://kubernetes.io/docs/concepts/scheduling-eviction. Último acceso: 04/02/2021.
- api-gateway
Nginx. What is an API Gateway? Sep. de 2020. URL: https://www.nginx.com/learn/api-gateway. Último acceso: 04/02/2021.
- microsoft-microsvcs
Microsoft Docs. Communication in a microservice architecture. Ene. de 2020. URL: https://docs.microsoft.com/en-us/dotnet/architecture/microservices/architect-microservice-container-applications/communication-in-microservice-architecture. Último acceso: 04/02/2021.
- wiki-kafka
Wikipedia. Apache Kafka. Ene. de 2021. URL: https://en.wikipedia.org/wiki/Apache_Kafka. Último acceso: 04/02/2021.
- apache-kafka
Apache Software Foundation. Apache Kafka. Nov. de 2020. URL: https://kafka.apache.org. Último acceso: 04/02/2021.
- helm-lib-charts
Helm - The package manager for Kubernetes. Library Charts. Ene. de 2021. URL: https://helm.sh/docs/topics/library_charts. Último acceso: 04/02/2021.
- flask
The Pallets Projects. Flask. 2021. URL: https://palletsprojects.com/p/flask. Último acceso: 04/02/2021.
- flaskRestful
Flask-RESTful Community. Flask-RESTful. 2021. URL: https://flask-restful.readthedocs.io/en/latest. Último acceso: 04/02/2021.
- miola20
Alberto Miola. Flutter Complete Reference: Create beautiful, fast and native apps for any device. Sep. de 2020. ISBN: 9798691939952.
- flutter-hot-reload
Flutter. Hot reload. Mayo de 2020. URL: https://flutter.dev/docs/development/tools/hot-reload. Último acceso: 09/02/2021.
- aot-wiki
Wikipedia. Compilación anticipada. Dic. de 2020. URL: https://es.wikipedia.org/wiki/Compilación_anticipada. Último acceso: 05/02/2021.
- flutter-web(1,2)
Flutter. Web FAQ. Oct. de 2020. URL: https://flutter.dev/docs/development/platform-integration/web. Último acceso: 05/02/2021.